Earlier this year, researchers tried teaching an AI to play the original Sonic the Hedgehog as part of the The OpenAI Retro Contest. The AI was told to prioritize increasing its score, which in Sonic means doing stuff like defeating enemies and collecting rings while also trying to beat a level as fast as possible. This dogged pursuit of one particular definition of success led to strange results: In one case, the AI began glitching through walls in the game’s water zones in order to finish more quickly.
It was a creative solution to the problem laid out in front of the AI, which ended up discovering accidental shortcuts while trying to move right. But it wasn’t quite what the researchers had intended. One of researchers’ goals with machine-learning AIs in gaming is to try and emulate player behavior by feeding them large amounts of player generated data. In effect, the AI watches humans conduct an activity, like playing through a Sonic level, and then tries to do the same, while being able to incorporate its own attempts into its learning. In a lot of instances, machine learning AIs end up taking their directions literally. Instead of completing a variety of objectives, a machine-learning AI might try to take shortcuts that completely upend human beings’ understanding of how a game should be played.
Victoria Krakovna, a researcher on Google’s DeepMind AI project, has spent the last several months collecting examples like the Sonic one. Her growing collection has recently drawn new attention after being shared on Twitter by Jim Crawford, developer of the puzzle series Frog Fractions, among other developers and journalists. Each example includes what she calls “reinforcement learning agents hacking the reward function,” which results in part from unclear directions on the part of the programmers.
“While ‘specification gaming’ is a somewhat vague category, it is particularly referring to behaviors that are clearly hacks, not just suboptimal solutions,” she wrote in her initial blog post on the subject. “A classic example is OpenAI’s demo of a reinforcement learning agent in a boat racing game going in circles and repeatedly hitting the same reward targets instead of actually playing the game.”
A few years back, computer science doctor Tom Murphy used high scores to try to teach AI programs how to play NES games. When an AI tried to get as high a score as possible, it ended up leading playing games like Tetris completely wrong, dropping pieces randomly as quickly as possible rather than in organized patterns to clear lines. That was because dropping each piece and moving onto the next generated a small increase to the computer’s score. In effect, it was unable to see the forest for the trees. The AI would even pause the game right before a final tetris piece would clog up the screen to prevent itself from ever losing.
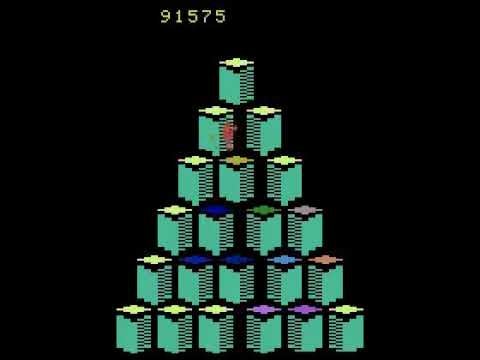
Another AI, which researchers Patryk Chrabaszcz, Ilya Loshchilov, Frank Hutter wrote about in a paper published in February, discovered a mysterious bug when it tried to rack up a high score in Q*bert. Between levels one and two the game paused, the platforms began to blink, and the AI player’s score started going up. Eventually it reached one million before the time limit was reached. The glitch, which players have been able to duplicate in tool-assisted-speedruns of the game, involves stepping on certain blocks before the level changes to cause the ending lto repeat indefinitely, boosting the player’s score each time.
At another point in its evolution, the Q*bert AI even took to killing itself to boost its score. After discovering a pattern of movement by which it could get enemies to follow it off a cliff in order to gain more points and an extra life, it continued to do just that for the rest of the session.
An especially deep cut from Krakovna’s database revolves around the 2000s research game NERO, where competing players had armies of robots whose intelligences evolved over the course of a match. In one particular match, the robots evolved to find a way to wiggle over the top of player-built walls by turning back and forth in a way that exploited a bug in the game’s engine. They had unintentionally discovered a way to break the game, showing both the shortcomings and occasional genius of machine learning AIs.
It’s this potential for self-experimentation that’s led the DeepMind project to invest so much in trying to learn complex games like Blizzard’s StarCraft II. It was revealed at BlizzCon 2017 that Google would be teaching its AI how to play the real-time strategy game, and though it hasn’t yet faced top human players, Blizzard announced at this year’s BlizzCon that it had so far managed to successfully beat the game’s AI on the hardest difficulty using advanced rushing strategies. DeepMind has already beaten some of the world’s best human players in Go, and taking on pros in games with more variables like StarCraft II will be the next test. Hopefully it doesn’t find a way to cheat.













